Adopt a zero trust network model for security
Big picture
Adopting a zero trust network model is best practice for securing workloads and hosts in your cloud-native strategy.
Value
Zero Trust Networks are resilient even when attackers manage to breach applications or infrastructure. They make it hard for attackers to move laterally, and reconnaissance activities easier to spot.
Organizations that embrace the change control model in this How-To will be able to tightly secure their network without imposing a drag on innovation in their applications. Security teams can be enablers of business value, not roadblocks.
Concepts
The network is always hostile
Zero Trust Networking is an approach to network security that is unified by the principle that the network is always assumed to be hostile. This is in direct contrast to perimeter and “segmentation” approaches that focus on separating the world into trusted and untrusted network segments.
Why assume the network is hostile? In many attack scenarios, it is.
- Attackers may compromise “trusted” parts of your network infrastructure: routers, switches, links, etc.
- Deliberate or accidental misconfiguration can route sensitive traffic over untrusted networks, like the public Internet.
- Other endpoints on a “trusted” network may be compromised: your application may share a network with thousands of other servers, tens of thousands of other containers, thousands of personal laptops, phones, etc.
Major breaches typically start as a minor compromise of as little as a single component, but attackers then use the network to move laterally toward high value targets: your company’s or customers’ data. In a zone or perimeter model, attackers can move freely inside the perimeter or zone after they have compromised a single endpoint. A Zero Trust Network is resilient to this threat because it enforces strong, cryptographic authentication and access control on each and every network connection.
Requirements of a Zero Trust Network
Zero Trust Networks rely on network access controls with specific requirements:
Requirement 1: All network connections are subject to enforcement (not just those that cross zone boundaries).
Requirement 2: Establishing the identity of a remote endpoint is always based on multiple criteria including strong cryptographic proofs of identity. In particular, network-level identifiers like IP address and port are not sufficient on their own as they can be spoofed by a hostile network.
Requirement 3: All expected and allowed network flows are explicitly allowed. Any connection not explicitly allowed is denied.
Requirement 4: Compromised workloads must not be able to circumvent policy enforcement.
Requirement 5: Many Zero Trust Networks also rely on encryption of network traffic to prevent disclosure of sensitive data to hostile entities snooping network traffic. This is not an absolute requirement if private data are not exchanged over the network, but to fit the criteria of a Zero Trust Network, encryption must be used on every network connection if it is required at all. A Zero Trust Network does not distinguish between trusted and untrusted network links or paths. Also note that even when not using encryption for data privacy, cryptographic proofs of authenticity are still used to establish identity.
How Calico and Istio implement Zero Trust Network requirements
Calico works in concert with the Istio service mesh to implement all you need to build a Zero Trust Network in your Kubernetes cluster.
Multiple enforcement points
When operating with Istio, incoming requests to your workloads traverse two distinct enforcement points:
- The host Linux kernel. Calico policy is enforced in the Linux kernel using iptables at L3-L4.
- The Envoy proxy. Calico policy is enforced in the Envoy proxy at L3-7, with requests being cryptographically authenticated. A lightweight policy decision sidecar called Dikastes assists Envoy in this enforcement.
These multiple enforcement points establish the identity of the remote endpoint based on multiple criteria (Requirement 2). The host Linux kernel enforcement protects your workloads even if the workload pod is compromised and the Envoy proxy bypassed (Requirement 4).
Calico policy store
The policies in the Calico data store encode the allow-list of allowed flows (Requirement 3).
Calico network policy is designed to be flexible to fit many different security paradigms, so it can express, for example, both Zero Trust Network-style allow-lists as well as legacy paradigms like zones. You can even layer both of these approaches on top of one another without creating a maintenance mess by composing multiple policy documents.
The How To section of this document explains how to write policy specifically in the style of Zero Trust Networks. Conceptually, you will begin by denying all network flows by default, then add rules that allow the specific expected flows that make up your application. When you finish, only legitimate application flows are allowed and all others are denied.
Calico control plane
The Calico control plane handles distributing all the policy information from the Calico data store to each enforcement point, ensuring that all network connections are subject to enforcement (Requirement 4). It translates the high-level declarative policy into the detailed enforcement attributes that change as applications scale up and down to meet demand, and evolve as developers modify them.
Istio Citadel Identity System
In Calico and Istio, workload identities are based on Kubernetes Service Accounts. An Istio component called Citadel handles minting cryptographic keys for each Service Account to prove its identity on the network (Requirement 2) and encrypt traffic (Requirement 5). This allows the Zero Trust Network to be resilient even if attackers compromise network infrastructure like routers or links.
How to
This section explains how to establish a Zero Trust Network using Calico and Istio. It is written from the perspective of platform and security engineers, but should also be useful for individual developers looking to understand the process.
Building and maintaining a Zero Trust Network is the job of an entire application delivery organization, that is, everyone involved in delivering a networked application to its end users. This includes:
- Developers, DevOps, and Operators
- Platform Engineers
- Network Engineers
- Security Engineers and Security Operatives
In particular, the view that developers build applications which they hand off to others to figure out how to secure is incompatible with a Zero Trust Network strategy. To function correctly, a Zero Trust Network needs to be configured with detailed information about expected flows---information that developers are in a unique position to know.
At a high level, you will undertake the following steps to establish a Zero Trust Network:
- Install Calico.
- Install Istio and enable Calico integration.
- Establish workload identity by using Service Accounts.
- Write initial allow-list policies for each service.
After your Zero Trust Network is established, you will need to maintain it.
Install Calico
Follow the install instructions to get Calico software running in your cluster.
Install Istio and enable Calico integration
Follow the instructions to Enable application layer policy.
The instructions include a “demo” install of Istio for quickly testing out functionality. For a production installation to support a Zero Trust Network, you should instead follow the official Istio install instructions. Be sure to enable mutually authenticated TLS (mTLS) in your install options by setting global.mtls.enabled to true.
Establish workload identity by using Service Accounts
Our eventual goal is to write access control policy that authorizes individual expected network flows. We want these flows to be scoped as tightly as practical. In a Calico Zero Trust Network, the cryptographic identities are Kubernetes Service Accounts. Istio handles crypto-key management for you so that each workload can assert its Service Account identity in a secure manner.
You have some flexibility in how you assign identities for the purpose of your Zero Trust Network policy. The right balance for most people is to use a unique identity for each Kubernetes Service in your application (or Deployment if you have workloads that don’t accept any incoming connections). Assigning identity to entire applications or namespaces is probably too coarse, since applications usually consist of multiple services (or dozens of microservices) with different actual access needs.
You should assign unique identities to microservices even if you happen to know that they access the same things. Your policy will be more readable if the identities correspond to logical components of the application. You can grant them the same permissions easily, and if in the future they need different permissions it will be easier to handle.
After you decide on the set of identities you require, create the Kubernetes Service Accounts, then modify your application configuration so that each Deployment, ReplicaSet, StatefulSet, etc. uses the correct Service Account.
Write initial allow-list policies for each service
The final step to establishing your Zero Trust Network is to write the policies for each service in your network. The Application Layer Policy Tutorial gives an overview of setting up policies that allow traffic based on Service Account identity.
For each service you will:
- Determine the full set of other identities that should access it.
- Add rules to allow each of those flows.
After a pod is selected by at least one policy, any traffic not explicitly allowed is denied. This implements the Zero Trust Network paradigm of an explicit allow-list of expected flows.
Determine the full set of identities that should access each service
There are several approaches to determining the set of identities that should access a service. Work with the developers of the application to generate this list and ensure it is correct. One approach is to create a flow diagram of your entire application. A flow diagram is a kind of graph where each identity is a node, and each expected flow is an edge.
Let’s look at an example application.
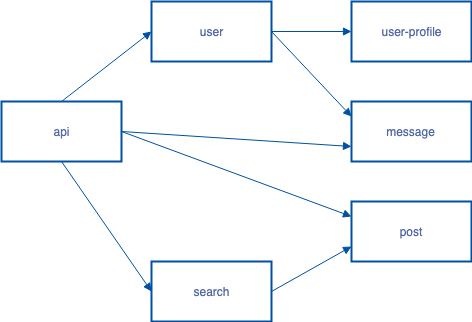
In this example, requests from end-users all flow through a service called api, where they can trigger calls to other services in the backend. These in turn can call other services. Each arrow in this diagram represents an expected flow, and if two services do not have a connecting arrow, the are not expected to have any network communication. For example, the only services that call the post service are api and search.
For simple applications, especially if they are maintained by a single team, the developers will probably be able to just write down this flow graph from memory or with a quick look at the application code.
If this is difficult to do from memory, you have several options.
- Run the application in a test environment with policy enabled. a. Look at service logs to see what connectivity has broken. b. Add rules that allow those flows and iterate until the application functions normally. c. Move on to the next service and repeat.
- Collect flow logs from a running instance of your application. Calico Enterprise can be used for this purpose, or the Kiali dashboard that comes with Istio. a. Process the flow logs to determine the set of flows. b. Review the logged flows and add rules for each expected flow.
- Use Calico Enterprise for policy, and put it into logging-only mode. a. In this mode “denied” connections are logged instead of dropped. b. Review the “denied” logs and add rules for each expected flow.
When determining flows from a running application instance, be sure to review each rule you add with application developers to determine if it is legitimate and expected. The last thing you want is for a breach-in-progress to be enshrined as expected flows in policy!
Write policies with allow rules for each flow
After you have the set of expected flows for each service, you are ready to write Calico network policy to allow-list those flows and deny all others.
Returning to the example flow graph in the previous section, let’s write the policy for the post service. For the purpose of this example, assume all the services in the application run in a Kubernetes Namespace called microblog. We see from the flow graph that the post service is accessed by the api and search services.
apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: post-allow-list
namespace: microblog
spec:
selector: svc == 'post'
types:
- Ingress
ingress:
- action: Allow
source:
serviceAccounts:
names: ['api', 'search']
namespaceSelector: app == 'microblog'
protocol: TCP
destination:
ports:
- 8080
Things to notice in this example:
-
Namespace
Create a Calico NetworkPolicy in the same namespace as the service for the allow-list (microblog).
metadata:name: post-allow-listnamespace: microblog -
Selectors
The selector controls which pods to apply policy. It should be the same selector used to define the Kubernetes Service.
spec:selector: svc == 'post' -
Service account by name
In the source: selector, allow api and search by name. An alternative to selecting service accounts by name, is by namespaceSelector (next example).
source:serviceAccounts:names: ['api', 'search'] -
Service account by namespaceSelector
Service Accounts are uniquely identified by name and namespace. Use a namespaceSelector to fully-qualify the Service Accounts you are allowing, so if names are repeated in other namespaces they will not be granted access to the service.
source:serviceAccounts:names: ['api', 'search']namespaceSelector: app == 'microblog' -
Rules
Scope your rules as tightly as possible. In this case we are allowing connection only on TCP port 8080.
destination:ports:- 8080
The above example lists the identities that need access to the post service by name. This style of allow-list works best when the developers responsible for a service have explicit knowledge of who needs access to their service.
However, some development teams don’t explicitly know who needs access to their service, and don’t need to know. The service might be very generic and used by lots of different applications across the organization---for example: a logging service. Instead of listing the Service Accounts that get access to the service explicitly one-by-one, you can use a label selector that selects on Service Accounts.
In the following example, we have changed the serviceAccount clause. Instead of a name, we use a label selector. The selector: svc-post == access label grants access to the post service.
apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: post-allow-list
namespace: microblog
spec:
selector: svc == 'post'
types:
- Ingress
ingress:
- action: Allow
source:
serviceAccounts:
selector: svc-post == 'access'
namespaceSelector: app == 'microblog'
protocol: TCP
destination:
ports:
- 8080
Define labels that indicate permission to access services in the cluster. Then, modify the ServiceAccounts for each identity that needs access. In this example, we would add the label svc-post == access to the api and search Service Accounts.
Whether you choose to explicitly name the Service Accounts or use a label selector is up to you, and you can make a different choice for different services. Using explicit names works best for services that have a small number of clients, or when you want the service owner to be involved in the decision to allow something new to access the service. If some other team wants to get access to the service, they call up the owner of the service and ask them to grant access. In contrast, using labels is good when you want more decentralized control. The service owner defines the labels that grant access to the service and trusts the other development teams to label their Service Accounts when they need access.
Maintain your zero trust network
The allow-list policies are tightly scoped to the exact expected flows in the applications running in the Zero Trust Network. If these applications are under active development the expected flows will change, and policy, therefore, also needs to change. Maintaining a Zero Trust Network means instituting a change control policy that ensures:
- Policies are up to date with application changes
- Policies are tightly scoped to expected flows
- Changes keep up with the pace of application development
It is difficult to overstate how important the last point is. If your change control process cannot handle the volume of changes, or introduces too much latency in deploying new features, your transition to a Zero Trust Network is very likely to fail. Either your senior leadership will choose business expediency and overrule your security concerns, or competitors that can roll out new versions faster will stifle your market share. On the other hand, if your change control process does keep pace with application development, it will bring security value without sacrificing the pace of innovation.
The size of the security team is often relatively small compared with application development and operations teams in most organizations. Fortunately, most application changes will not require changes in security policy, but even a small proportion of changes can lead to a large absolute number when dealing with large application teams. For this reason, it is often not feasible for a member of the security team to make every policy change. A classic complaint in large enterprises is that it takes weeks to change a firewall rule---this is often not because the actual workflow is time consuming but because the security team is swamped with a large backlog.
Therefore, we recommend that the authors of the policy changes be developers/DevOps (i.e. authorship should “shift left”). This allows your change control process to scale naturally as your applications do. When application authors make changes that require policy changes (say, adding a new microservice), they also make the required policy changes to authorize the network activity associated with it.
Here is a simplified application delivery pipeline flow.
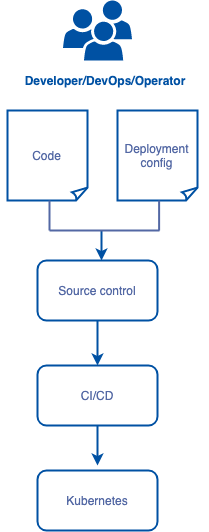
Developers, DevOps, and/or Operators make changes to applications primarily by making changes to the artifacts at the top of the diagram: the source code and associated deployment configuration. These artifacts are put in source control (e.g. git) and control over changes to the running applications are managed as commits to this source repository. In a Kubernetes environment, the deployment configuration is typically the objects that appear on the Kubernetes API, such as Services and Deployment manifests.
What you should do is include the NetworkPolicy as part of those deployment config artifacts. In some organizations, these artifacts are in the same repo as the source code, and in others they reside in a separate repo, but the principle is the same: you manage policy change control as commits to the deployment configuration. This config then works its way through the delivery pipeline and is finally applied to the running Kubernetes cluster.
Your developers will likely require training and support from the security team to get policy correct at first. Many trained developers are not used to thinking about network security. The logical controls expressed in network policy are simple compared with the flexibility they have in source code, so the primary support they will need from you is around the proper security mindset and principles of Zero Trust Networks. You can apply a default deny policy in your cluster to ensure that developers can’t simply forget to apply their own allow-listed policy.
You may wish to review every security policy change request (aka pull request in git workflows) at first. If you do, then be sure you have time allotted, and consider rolling out Zero Trust Network policies incrementally, one application or service at a time. As development teams gain confidence you can pull back and have them do their own reviews. Security professionals can do spot checks on change requests or entire policies to ensure quality remains high in the long term.