Cluster mesh
This guide explains the concept of cluster mesh and how you can use Calico to enable multi-cluster communications, service discovery, and federated endpoints. For a hands-on experience you can work through our self-paced lab tutorial Kubernetes multi-cluster management.
Overview
What is cluster mesh?
Cluster mesh enables cross-cluster communication in a Kubernetes-native way.
Pods and workloads in one cluster can easily access and use services and endpoints from another cluster as if they’re local, meaning you can access them with their local DNS records and use kubectl to interact with them.
These are known as federated services and endpoints
When to use cluster mesh
If you already have, or are planning to build, an environment that has multiple clusters and:
- You want to share, or federate, services between clusters.
- You need to use network policies to manage access to federated services and endpoints to meet compliance requirements.
- You need high availability, disaster recovery, or low latency for your services.
- You don’t want to set up or maintain a complicated service mesh.
Federating services and endpoints between clusters
Federated services in Kubernetes allow you to access and discover services from other clusters as if they exist in your local cluster. This provides a Kubernetes-native experience because you can connect to services and reference them through their annotations and service names.
Securing federated services and endpoints for compliance
When services are federated, you can apply network policies to the shared services as if they are local to the cluster using labels and selectors, rather than IP addresses. This helps you achieve compliance by ensuring that you have the required security access controls in place to protect intercluster services. The egress access control use case expands on this topic.
Improving networking performance
Federated services provide a low-latency solution because traffic travels directly to the service in the remote cluster using an overlay network, without the need for an additional hop through ingress controllers, load balancers, or other routes. This is beneficial for low-latency applications that are distributed or communicate across different clusters. Calico Enterprise cluster mesh is implemented in Kubernetes at the network layer, based on pod IPs.
Reducing downtime
High availability means your service should be available continuously with minimal downtime. Federated services can be backed by geographically distributed clusters in different availability zones, regions, or clouds. This ensures that if one of the services goes down, there are others that are still up and running that can respond to requests without intervention. A workload accessing the federated service will not be interrupted.
Fast recovery
Federated services are automatically discovered by clusters that are meshed together. In the event of a disaster, users regain access as soon as the recovery or backup service is up and running with the correct namespace and annotations. With disaster recovery, some service interruption is expected, but federating services with cluster mesh means that clients can resume connections quickly without manual reconfigurations.
Avoiding service mesh
A Kubernetes service mesh is a dedicated infrastructure layer designed to manage, observe, and control communication between microservices within a Kubernetes cluster. A service mesh is designed to improve the overall reliability, security, and observability of the microservices that make up a complex, distributed application. But installing and managing a service mesh requires specialist expertise, and it's sometimes not such a great time investment for the sake of a small set of service mesh functionality. Using an overlay network to achieve cross-cluster communication can be a faster, simpler solution without the overhead of a service mesh.
Support for cluster mesh
Cluster mesh is supported in Calico Enterprise or Calico Cloud out-of-box.
Calico Open Source does not include cluster mesh, but you can get much of the same functionality though other means. You can watch this CNCF webinar recording, which shows BGP routing, peering, and Calico BIRD integration in the cloud with Calico Open Source.
To see what’s possible with all Calico products, you can read this blog post “What is a Kubernetes cluster mesh and what are the benefits?”
Cluster mesh concepts
It's worth the time to make sure you understand some core components and configurations before you implement this in your own environment.
Cluster mesh networking
Calico Enterprise or Calico Cloud cluster mesh is implemented in Kubernetes at the network layer, based on pod IPs (layer 3 of the OSI model). There are two options for implementing this: overlay networking and underlay networking.
An overlay network creates a virtual network on top of a physical network, allowing pods to communicate directly with each other. This is beneficial when the underlying network cannot easily be made aware of other workload IPs, for example, across multiple VPCs or subnets. For cluster mesh, packets use VXLAN encapsulation.
Calico Enterprise or Calico Cloud can automatically extend the VXLAN overlay when RemoteClusterConfiguration objects are created.
With an underlay network, such as BGP, routing information between nodes is shared between peers. This allows peers, or nodes, to ensure their workloads are communicable, because pod CIDRs are advertised to the underlying network, and traffic can be routed to them successfully. This means pods can communicate using their IP addresses, but can also use Kubernetes nomenclature for targeting or selecting endpoints.
Calico cluster mesh offers both BGP (underlay) and overlay, and they can be used together. Configuring the underlay networking ensures that services and workloads are routable between nodes, and the overlay enables the Kubernetes-native approach of communicating.
Cluster types
When configuring cluster mesh you might see a reference to a local or remote cluster.
Each cluster in the cluster mesh can act as both a local and a remote cluster.
Local clusters are configured to retrieve endpoint and routing data from remote clusters (via RemoteClusterConfiguration).
Remote clusters authorize local clusters to retrieve endpoint and routing data.
RemoteClusterConfiguration
The RemoteClusterConfiguration object is the resource that configures a local cluster to sync resources from a remote cluster.
It describes how a local cluster establishes that connection to the remote cluster, through which resources are synced.
The resources synced through this one-way connection enable the local cluster to reference a remote endpoint identity and establish cross-cluster overlay routes.
If the remote cluster needs to sync resources that exist in the local cluster, it will need its own RemoteClusterConfiguration.
In this case, the remote cluster becomes the local cluster, and vice versa.
Typha
Typha is a component of Calico that caches the datastore state and maintains a single datastore connection for all its clients. Typha is the component that will be accessing the remote cluster. Typha logs will contain the remote cluster connection status.
Implementing cluster mesh
In order to set up a cluster mesh with Calico Enterprise or Calico Cloud, you need to make sure that you are using the Calico CNI and that you have ensured pod IP routability.
An overview of the key steps to set up cluster mesh are outlined below.
This is not a prescriptive list, and it doesn’t include any specific networking prerequisites that will vary depending on your environment. Refer to our detailed instructions that are available in either the Calico Enterprise or Calico Cloud documentation.
Set up multi-cluster communication
Multi-Cluster communication is required to make sure that pods are routable between clusters.
The first step is to create a dedicated kubeconfig file for each cluster in the mesh that allows for connection and authentication with each other.
Tigera provides manifests that can be applied to create a service account for remote clusters to authenticate, and cluster roles and cluster role bindings if RBAC is enabled.
The kubeconfig file will look something like this:
apiVersion: v1
kind: Config
users:
- name: tigera-federation-remote-cluster
user:
token: <YOUR-SERVICE-ACCOUNT-TOKEN>
clusters:
- name: tigera-federation-remote-cluster
cluster:
certificate-authority-data: <YOUR-CERTIFICATE-AUTHORITY-DATA>
server: <YOUR-SERVER-ADDRESS>
contexts:
- name: tigera-federation-remote-cluster-ctx
context:
cluster: tigera-federation-remote-cluster
user: tigera-federation-remote-cluster
current-context: tigera-federation-remote-cluster-ctx
For detailed instructions on correctly creating these kubeconfig files, follow the documentation for either Calico Enterprise or Calico Cloud.
The RemoteClusterConfiguration object
RemoteClusterConfiguration objects enable synchronization between clusters by creating the correct roles, role bindings, and secrets that enable a local cluster to access a remote cluster.
The RemoteClusterConfiguration example shown below specifies the secret used to access cluster B, and the overlay routing mode that toggles the establishment of cross-cluster overlay routes.
apiVersion: projectcalico.org/v3
kind: RemoteClusterConfiguration
metadata:
name: cluster-b
spec:
clusterAccessSecret:
name: remote-cluster-secret-name
namespace: <secret-namespace>
kind: Secret
syncOptions:
overlayRoutingMode: Enabled
If you choose not to use an overlay network with VXLAN encapsulation and instead configure it manually, this will be disabled:
syncOptions:
overlayRoutingMode: Disabled
If you are setting up an unencapsulated cluster mesh and you have IP pools in cluster A with NAT-outgoing enabled, and workloads in that pool will egress to workloads in cluster B, you need to instruct Calico Enterprise or Calico Cloud to not perform NAT on traffic destined for IP pools in cluster B.
You can achieve this by creating a disabled IP pool in cluster A for each CIDR in cluster B. This IP pool should have NAT-outgoing disabled. For example:
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: clusterB-main-pool
spec:
cidr: <Cluster B CIDR>
disabled: true
You can check remote cluster connection status inside the Typha logs:
Run the following command:
kubectl logs deployment/calico-typha -n calico-system | grep "Sending in-sync update"
You should see an entry for each RemoteClusterConfiguration object in the local cluster.
These steps will need to be performed on both the local and remote clusters to allow bidirectional synchronization.
For detailed instructions on correctly creating the RemoteClusterConfiguration object, follow the documentation for either Calico Enterprise or Calico Cloud.
Enable multi-cluster service discovery and federation
The Tigera controller will automatically create and manage federated endpoints after you configure multi-cluster communication.
These endpoints across the mesh can be consolidated into a federated service.
A federated service looks similar to a regular Kubernetes service, but, instead of using a pod selector, it uses an annotation to specify the services to federate. For example:
apiVersion: v1
kind: Service
metadata:
name: my-app-federated
namespace: default
annotations:
federation.tigera.io/serviceSelector: run == "my-app"
spec:
ports:
- name: my-app-ui
port: 8080
protocol: TCP
type: ClusterIP
Only services in the same namespace as the federated service are included.
For detailed instructions on correctly creating the federated services, follow the documentation for either Calico Enterprise or Calico Cloud.
Viewing intercluster services
Once you’ve configured federated services you can validate the services and endpoints by running kubectl get services and kubectl get endpoints for the relevant namespaces in both local and remote clusters.
For a more visual representation, Calico Enterprise and Calico Cloud provide unified observability, allowing you to see federated services as if they’re in your local cluster. You can read more about observability in our use case page.
You can use the dynamic service and threat graph to see all service resources behind a federated service, and which other endpoints they are interacting with.
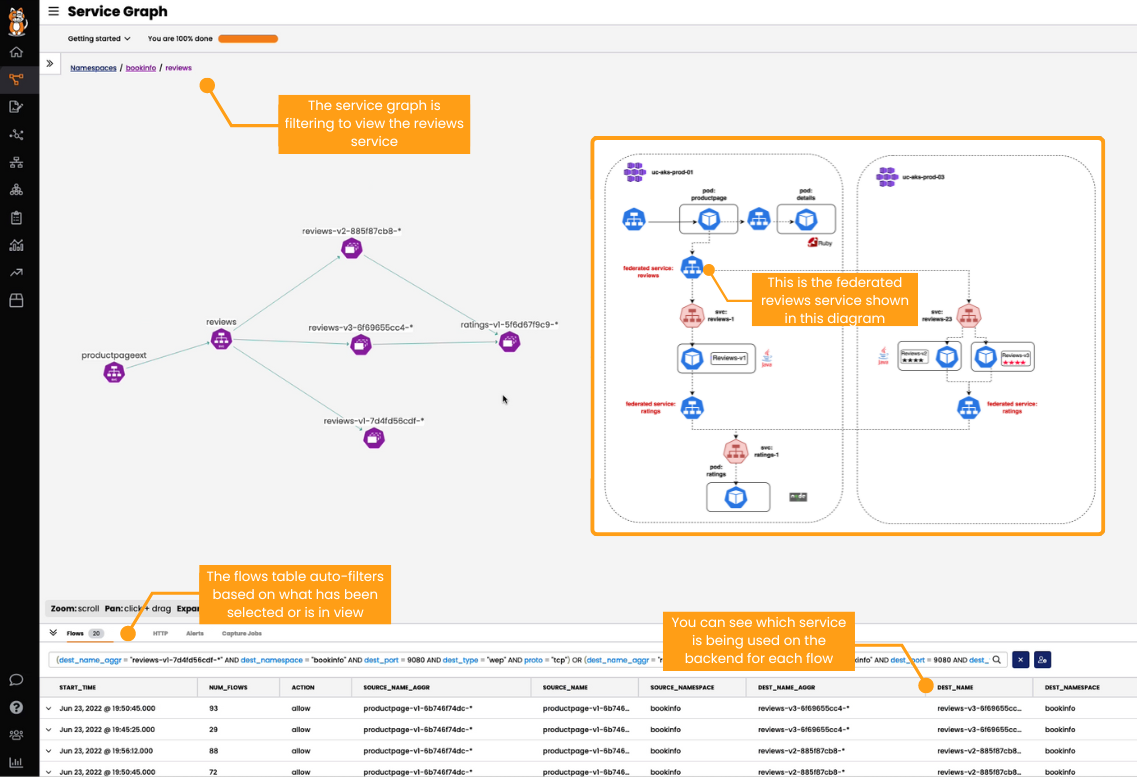
The flows table automatically filters based on the view inside service graph, and you can easily determine which services behind a federated service are being used for each flow.
If you need to identify issues with federated services, having a holistic view of all services (federated and local) within a cluster speeds up that process.
You can see an example of this in action by watching the video Observability for Federated Services (look for the bookinfo application).
Using cluster mesh
Using federated services
In the example below, two clusters, uc-aks-prod-01 and uc-aks-prod-03, have been meshed together.
The uc-aks-prod-03 cluster contains a reviews service that the application needs.
The application has two federated services: reviews and ratings.
The reviews service has been federated in cluster uc-aks-prod-01, and there are three services backing the federated service, which we can see in the diagram.
Reviews-v1 exists in uc-akd-prod-01, and Reviews-v2 and Reviews-v2 exist in cluster uc-aks-prod-03.
The federated service manifest is looking for any services in the bookinfo namespace with the label app: reviews using the annotation federation.tigera.io/serviceSelector: app == "reviews".
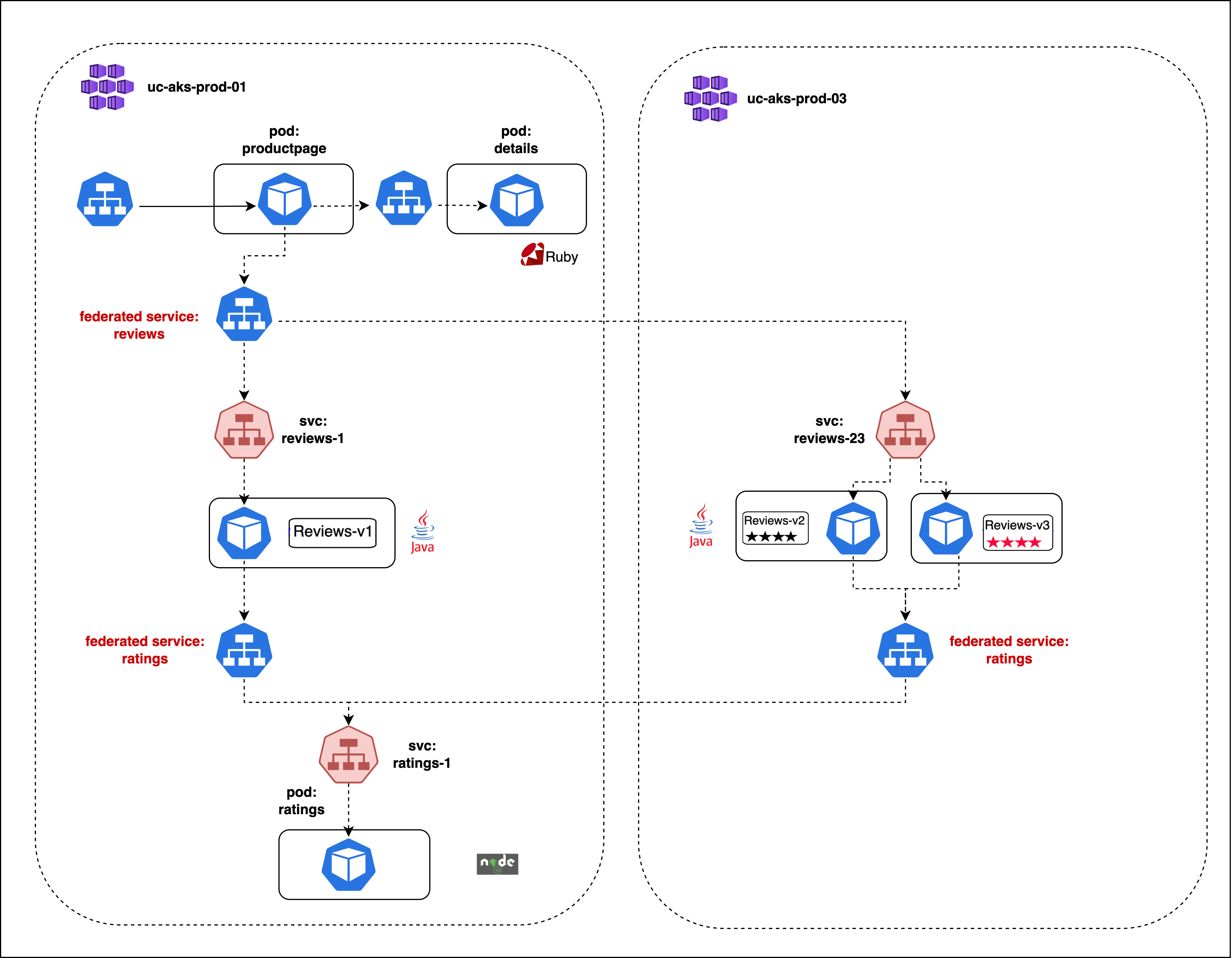
In uc-aks-prod-01, running a kubectl get services will show both the federated reviews and ratings services, as well as the backing services.
In uc-aks-prod-03, running a kubectl get services will show the federated ratings service, as well as the backing service reviews-23.
Running kubectl get endpoints in uc-aks-prod-01 will show the federated reviews service with three endpoints (the IP addresses of Reviews-v1, Reviews-v2, and Reviews-v3) and the federated ratings services with one endpoint (the local ratings-1 service).
Running kubectl get endpoints in uc-aks-prod-03 will show the reviews-23 service with two endpoints (the IP addresses of Reviews-v2 and Reviews-v3) and the federated ratings services with one endpoint (the remote ratings-1 service).
You may prefer to watch the above examples for federated endpoints or federated services in video format, which takes you through the configuration and validation process.
Maintaining high availability and disaster recovery
To ensure that you’re set up for high availability, configure remote clusters on geographically distributed infrastructure to build redundancies. If one availability zone, region, or cloud experiences an outage, other backing services will not be affected, and the federated service will remain operational.
For disaster recovery, ensure that the recovery components are configured correctly so that when they are brought online, they will be discovered and the endpoints will be available for federated services. You will need to ensure that multi-cluster communication is configured, along with services having the correct labels in the correct namespaces.
Once the backup clusters and services are running, the federated service will continue to work as expected, and the service consumer may have no idea that the endpoints backing the federated service were replaced (apart from an interruption in service). No extra configuration is required.
Cluster mesh is proven to work in a multiregion Cockroach DB deployment, where database clients need low latency and database administrators need to enforce data protection controls to restrict access and meet regulatory requirements. The blog post “Build and secure multi-cluster CockroachDB using the Calico cluster mesh: A step-by-step guide” shows you how to replicate a multiregion CockroachDB deployment with endpoint federation.
Another example, using Redis, shows how cluster mesh can federate services across multiple clusters to ensure continuous uptime. Redis, just like CockroachDB, has been built specifically for Kubernetes environments. By federating an Active-Active Redis service, any services that rely on Redis will be able to access any active instances through the federated service, even if the Redis service in their local cluster were to become unavailable. You can read more, and see instructions to set up the environment for yourself, in our blog post “Achieving high availability (HA) Redis Kubernetes clusters with Calico cluster mesh in Microsoft AKS”.
Without cluster mesh you would need to create and manage a separate ingress or load balancer solution to achieve something similar, but you would lose the ability to target services using their DNS names, labels, or annotations. This would not be desirable for applications that require low latency, because there would be an additional hop when the traffic is routed through an ingress or load balancer.
Meeting compliance requirements and securing federated services
One of the key requirements for most compliance or regulatory frameworks is to implement workload access controls, and this extends to federated services. Using cluster mesh with an overlay network allows network policy to be written and applied in the local cluster containing rules that reference federated services or endpoints using identity-aware labels and selectors. Without an overlay network or cluster mesh, policies have to be written targeting pod IP addresses, which is not a best practice given that pod IP addresses are often dynamic This leads to service interruptions or security risks if workloads within clusters are not adequately protected.
This is discussed in detail in the microsegmentation and egress access controls use case pages, as well as our resources on compliance.
When applying network security policies in a cluster, there is no distinction between local or remote services or endpoints, and the policies will apply as long as the selector correctly matches an endpoint. Network policies should be applied in both remote and local clusters for comprehensive endpoint coverage.
In the following example, cluster A (an application cluster) has a network policy that governs outbound connections to cluster B (a database cluster).
apiversion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
name: default.app-to-db
namespace: myapp
spec:
# The main policy selector selects endpoints from the local cluster only.
selector: app == 'backend-app'
tier: default
egress:
- destination:
# Rule selectors can select endpoints from local AND remote clusters.
selector: app == 'postgres'
protocol: TCP
ports: [5432]
action: Allow
You can explore an example of securing and isolating federated endpoints in this walkthrough.
Ready to get started with Cluster Mesh? Contact us.